Welcome to Scott Takes
- Be kind.
- Make with others for others.
- Strong body, strong mind.
- Eat right, sleep well.
What is this? Where am I?
A collection of flim-flam and riff-raff entitled with a pun I couldn’t resist.
Who are you?
Classics 📜
Technical writing I don’t believe will ever get old.
REQUIRED
RECOMMENDED
- A Career Cold Start Algorithm
- Collective Code Construction Contract (C4) and hintjens’ annotations
- Fallacies of distributed computing
- The Heilmeier Catechism
- Lumpers and splitters, I am a lumper.
- Network protocols, sans I/O
- The Pragmatic Programmer
- Release It!
- Software Aging and Software Rejuvenation
- I once tried to pithily sell this in a presentation entitled “Just Die Already”
SHOULD NOT
RFCs 🤞
Evergreen content of prurient interest to the general public
Accepted
- Modular Errors with Rust’s thiserror
Upon further research, Alex Fedoseev in thiserror, anyhow, or How I Handle Errors in Rust Apps said everyting I just did, but better. - The Little Stranger
A tutorial on the use of feature flags to stage a rollout
Informational
…
In Review
- Manual programming
- Dependency cooldowns are unfair; we should use phased rollouts instead
Wherein I begin to feel like a one trick pony
Draft
- Interceptors Are Functions Too
As is often the case, I believe a complicated object-oriented pattern obscures the simple functional gem within it.
Abandoned
- The wildly misunderstood reconsider (some) pre-commit checks in an era of cheap automation
Manual programming
(⚠️ Poe’s Law Warning: the following is satire of antirez’s Automatic programming.)
In my keynote speeches, for some time now I started to refer to the process of writing software using junior engineer assistance (soon to become just “the process of writing software”, I believe) with the term “Managed Programming”.
In case you didn’t notice, managed programming produces vastly different results with the same programmers depending on the person that is guiding the process with their intuition, design, continuous steering and idea of software.
Please, stop saying “my report coded this software for me”. Hands-off management is the process of generating software using a programmer without being part of the process at all. You describe what you want in very general terms, and the programmer will produce whatever happens to be the first idea/design/code they would spontaneously, given their background, habits, the specific fads that happened to dominate in that year’s conferences, and so forth. The hands-off manager will, at most, report things not working or not in line with what they expected.
When the process is actual software production where you know what is going on, remember: it is the software you are producing. Moreover remember that the education and past experience, while not the only part where the programmer learns (on-the-job learning has its big weight) was produced by people, so we are not appropriating something else. We can pretend employee-written code is “ours”, we have the right to do so. Education is, actually, our collective gift that allows many individuals to do things they could otherwise never do, like if we are now linked in a collective mind, in a certain way.
That said, if hands-off management is the process of producing software without much understanding of what is going on (which has a place, and democratizes software production, so it is totally ok with me), managed programming is the process of producing software that attempts to be high quality and strictly following the producer’s vision of the software (this vision is multi-level: can go from how to do, exactly, certain things, at a higher level, to stepping in and tell the programmer how to write a certain function), with the help of junior engineer assistance. Also a fundamental part of the process is, of course, what to do.
I’m a manager, and I use managed programming. The code I generate in this way is mine. My code, my output, my production. I, and you, can be proud.
If you are not completely convinced, think to Redis. In Redis there is not much technical novelty, especially at its start it was just a sum of basic data structures and networking code that every competent system programmer could write. So, why it became a very useful piece of software? Because of the ideas and visions it contained.
Programming is now managed, vision is not (yet).
Dependency cooldowns are unfair; we should use phased rollouts instead
Note
I’m bad at writing and implicitly make the bold assumption of correlations at 00:00 UTC. I’ve made minor changes from the original draft to emphasise that point.
It was a sunny morning in Melbourne on March 31st. Developers starting their workday were sipping their flat whites as they waited for npm install to finish. You know the rest of this story. The Axios supply chain compromise was live from 00:21 to 03:15 UTC and disproportionately hit the eastern hemisphere. In the aftermath, the quiet calls for dependency cooldowns almost overnight became industry best practice.
Cooldowns work against fast-acting supply-chain attacks. But they have an awkward property: they implicitly rely on someone else installing first. In common (mal)practice, that “someone else” means Asia-Pacific:
- 00:00 UTC
- 08:00 in China
- 09:00 in Tokyo
- 11:00 in Sydney
I propose that instead of “everyone waits N days,” package managers should deterministically map projects into a rollout window based on stable inputs: a project-specific identifier, package name, version, and artifact digest. The result is a globally distributed adoption curve rather than timezone-based canaries.
If you prefer code to words, here’s a gist that demonstrates the idea.
First, let’s consider three other communities that do things differently:
Antivirus
In April 2010, McAfee 5958 bricked a whole lot of Windows XP installs. The response was phased rollouts, not “everyone wait 24 hours before updating antivirus definitions.” They were in a similar situation; the vendors are smart but most of their customers are unsophisticated. Vendors invest in testing and monitoring. And when something goes wrong, vendors are usually the first to find out.
OS and firmware
CrowdStrike Falcon crashed 8.5 million computers in one day. Biggest crash in history, front page New York Times, July 20 2024.
That update went out at 04:09 UTC, the middle of the business day in Oceania and Asia. One of the biggest lessons learned was to “release gradually across increasing rings of deployment.” Of course, many of us just felt bad that big enterprises were struck by big enterprise problems. But consider that in 2018, Windows 1809 was the first update that used a ML-targeted phased rollout after widespread data loss.
Feature flags
The weirdest part for me as I read all the cooldown buzz was that we don’t use cooldowns for our own applications. We deploy to small cohorts, monitor, and then gradually ramp up traffic. The Continuous Delivery community boiled it down to a catchy phrase: decoupling deployment from release.
The Proposal
Package registries do have fundamental differences from the above examples:
- OS updates work because the vendor controls publication and distribution
- Package registries are pull-based; they don’t directly decide who gets what artifact
- Therefore: any phased rollout logic must live on the project-side
The mechanism is simple, each project independently derives a hash from stable inputs:
- A unique
project_id - The fully qualified
packagename - The semver package
version - The artifact
digest
The hash is then mapped onto a rollout window; my example code uses (14 days) * sqrt(h) so that the release curve is biased toward earlier adoption while still leaving a long tail for detection:
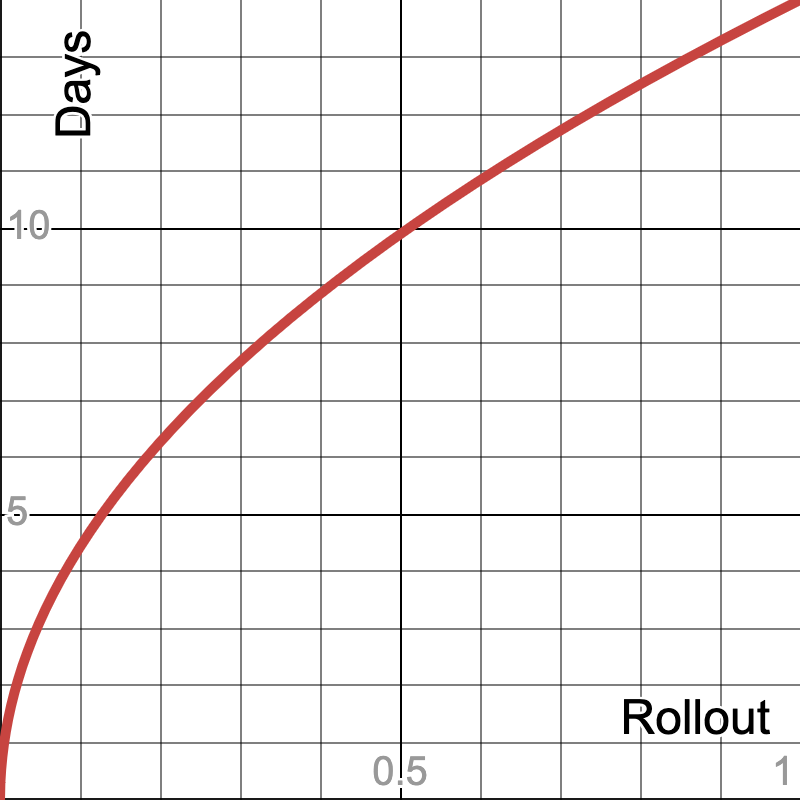
This results in globally distributed and effectively random adoption without any registry coordination. As a worked example, suppose two applications both depend on axios@1.14.1. One installs it after 4 hours, another after 5 days, and everyone has it after 14 days. The malicious release spreads through a random global subset first instead of following the sun. The tradeoff is slower convergence on newly published versions, especially for low-download packages. But cooldowns have the same tradeoff; phased rollouts just distribute it more fairly.
It’s also important to note that this proposal deliberately changes when projects adopt artifacts, not which artifacts they resolve. Existing lockfile and reproducibility guarantees remain once a version is selected. And security fixes still warrant different rollout policies.
What comes next
I thought of ways to overcomplicate this idea. Public attestation logs for canary reports? Cohort-aware tooling? Cross-ecosystem hash conventions? All cool, but I don’t want to takeaway from the heroic efforts spent on even better mitigations like:
- Capability sandboxing
- SBOMs
- Runtime monitoring
- Reading diffs
In summary, cooldowns reduce risk, but they don’t remove the fact that someone still has to go first. Other parts of the industry learned to use phased rollouts. Package ecosystems should learn the same lesson.
Hacks 🙈
It could be that the purpose of my life is only to serve as a warning to others.
- update
Any sufficiently complicated shell script contains an ad hoc, informally-specified, bug-ridden, slow implementation of half of nix.